
Hi there! I am TEJA
How can I assist you today

.png)
Retrieval-Augmented Generation (RAG) is an advanced AI architecture that combines two key components:
1. A retriever to fetch relevant information from an external knowledge source.
2. A generator (a large language model) to create human-like responses using that information.
Unlike traditional language models that rely only on internal training, RAG can pull in fresh, factual data from outside sources — making it smarter, more accurate, and less prone to hallucinations.
RAG is ideal for any task that requires current, factual, or domain-specific information.
Examples include:
- Customer Support Chatbots
- Search Engines
- Enterprise Knowledge Assistants
- Scientific/Medical Question Answering
- Document Summarization with References
- Legal Document Analysis
1. User Query
- User asks a question (e.g., "What causes global warming?")
2. Retriever
- Converts the query into an embedding
- Searches a document store (e.g., vector database)
- Retrieves the Top-K relevant texts
3. Fused Input
- The system combines the original question with the retrieved texts
- Creates a new prompt with richer context
4. Generator (LLM)
- A language model (e.g., GPT, T5, BART) uses this fused input
- Generates a natural, fact-based answer
5. Final Output
- The answer is returned to the user, grounded in actual documents
- Reduces hallucinations
- Allows up-to-date, dynamic knowledge injection
- More scalable than retraining LLMs
- Great for specialized, high-trust domains
- If retrieval quality is low, output suffers
- Context length limits in LLMs
- High compute cost for large-scale implementations

Retrieval-Augmented Generation (RAG) is an advanced AI architecture that combines two key components, a retriever to fetch relevant information from an external knowledge source and a generator (a large language model) to create human-like responses using that information.
In the era of Generative AI, the quality and scale of data processing have become more critical than ever. While sophisticated language models and ML algorithms steal the spotlight, the behind-the-scenes work of data preparation remains the unsung hero of successful AI implementations. From cleaning inconsistent formats to transforming raw inputs into structured information, these preparatory steps directly impact model performance and output quality. However, as data volumes grow exponentially, traditional sequential processing approaches quickly become bottlenecks, turning what should be one-time tasks into resource-intensive operations that delay model training and deployment. For organizations working with moderate to large datasets—too small to justify a full Hadoop or Spark implementation, yet too unwieldy for single-threaded processing—finding the middle ground of efficient parallelism has become essential for maintaining agile AI development cycles.
In the technical products sales domain, we faced a classic challenge: building a RAG-based GenAI chatbot capable of answering technical queries by leveraging historical customer service email conversations. Our analysis showed that approximately 65% of customer inquiries were repetitive in nature, making this an ideal candidate for automation through a modern GenAI solution.
The foundation of any effective AI system is high-quality data, and in our case, this meant processing a substantial volume of historical email conversations between customers and technical experts. As is often the case with real-world AI implementations, data preparation emerged as the most challenging aspect of the entire process.
Our email data resided in two distinct sources:
Together, these sources comprised approximately 1 million email threads with a total data footprint of around 400GB. The sheer volume made even simple operations time-consuming when approached sequentially.
Our data preparation task involved multiple steps:
The end goal was to transform this raw, unstructured data into a clean, structured corpus that could serve as the knowledge base for our RAG (Retrieval-Augmented Generation) system. With properly processed data, the chatbot would be able to retrieve relevant historical conversations and generate accurate, contextually appropriate responses to customer inquiries.
Let's examine the data processing implementation we initially developed to handle these email sources.
Our approach to processing the email data required handling two distinct sources through separate workflows, as illustrated below:
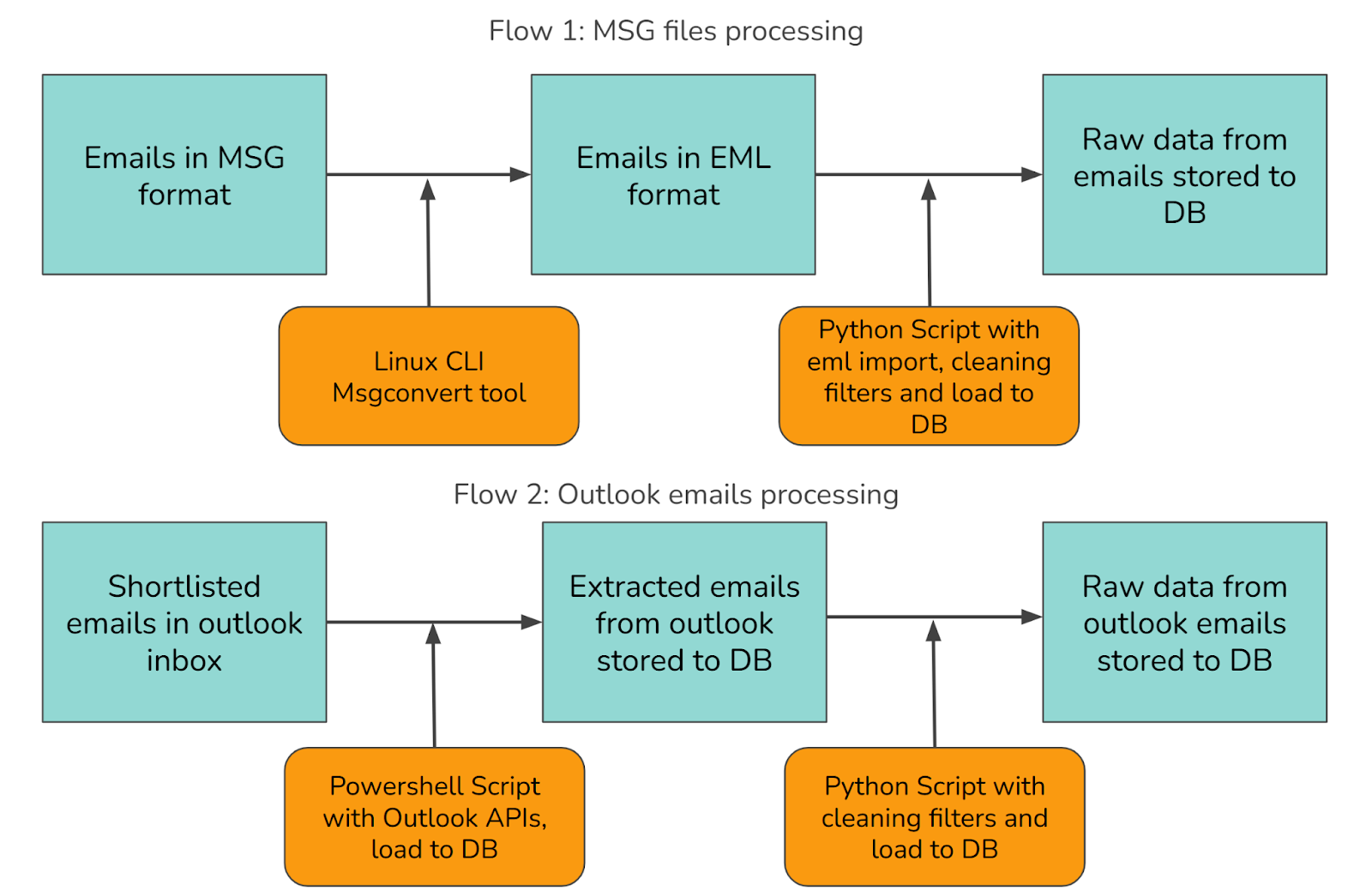
We needed to process emails from two primary sources:
To handle these diverse sources efficiently, we developed two parallel processing flows:
Since msg format is proprietary to Microsoft, we couldn't directly load it in a python script for content extraction. The parsers in scripting languages weren't good enough. Then we found a linux cli tool popular for this purpose msgconvert which can convert msg files into an open format eml files.
Example usage:
msgconvert /path/to/msg_file.msg --outfile /path/to/eml_file.eml
Here's a high level code snippet for sequential eml parsing, cleaning and save to db:
#!/usr/bin/env python3
import os
from pathlib import Path
import argparse
from tqdm import tqdm
def process_single_email(file_path):
"""
Process a single email file
- Parse the email
- Extract relevant data
- Transform content as needed
"""
# Implementation details abstracted away
email_data = parse_email_file(file_path)
if email_data:
return transform_email_data(email_data)
return None
def parse_email_file(file_path):
"""Parse an email file and return structured data"""
# Implementation details abstracted away
return {...} # Email data dictionary
def transform_email_data(email_data):
"""Process and transform email data"""
# Implementation details abstracted away
return {...} # Processed email data
def save_to_database(processed_data):
"""Save processed email data to database"""
# Implementation details abstracted away
pass
def main():
# Parse command-line arguments
parser = argparse.ArgumentParser(description="Process email files sequentially")
parser.add_argument("--dir", type=Path, default=Path.cwd(), help="Directory with email files")
parser.add_argument("--db-name", default="emails", help="Database name")
args = parser.parse_args()
# Get list of email files
email_files = list(args.dir.glob("*.eml"))
# Initialize database connection
db = initialize_database(args.db_name)
# Process emails sequentially with progress bar
results = []
for file_path in tqdm(email_files, desc="Processing emails"):
processed_data = process_single_email(file_path)
if processed_data:
results.append(processed_data)
# Save all results to database
save_to_database(results)
The above script shows a traditional sequential approach to processing email files:
This approach is straightforward but can be slow when dealing with many files, as each file must be fully processed before moving to the next one.
Outlook provides programmatic access and APIs via powershell and many other languages. We felt powershell is well suited and integrated for this purpose given the complexity of navigating through the Microsoft ecosystem. Here's the Outlook APIs documentation for reference.
# High-level script for extracting emails from Outlook folders and saving to SQLite
# Configuration
$DatabasePath = "C:\path\to\emails.db"
$FolderName = "Inbox"
function Initialize-Database {
param ($dbPath)
# Load SQLite assembly and create connection
# Implementation details abstracted away
# Return the connection object
return $connection
}
function Process-SingleEmail {
param ($emailItem, $dbConnection)
# Extract email properties
$subject = $emailItem.Subject
$body = $emailItem.Body
$htmlBody = $emailItem.HTMLBody
$receivedDate = $emailItem.ReceivedTime
# Save to database
Save-EmailToDatabase -emailData @{
Subject = $subject
Body = $body
HtmlBody = $htmlBody
ReceivedDate = $receivedDate
} -attachments $emailItem.Attachments -dbConnection $dbConnection
# Return success
return $true
}
function Save-EmailToDatabase {
param ($emailData, $attachments, $dbConnection)
# Save email data to database
# Implementation details abstracted away
# Save attachments
foreach ($attachment in $attachments) {
# Save attachment to database
# Implementation details abstracted away
}
}
function Main {
# Initialize Outlook
$outlook = New-Object -ComObject Outlook.Application
$namespace = $outlook.GetNamespace("MAPI")
# Connect to database
$dbConnection = Initialize-Database -dbPath $DatabasePath
# Get the target folder
$folder = $namespace.Folders.Item(1).Folders.Item($FolderName)
# Get all items
$totalItems = $folder.Items.Count
Write-Host "Found $totalItems emails to process"
# Process each email sequentially
$processedCount = 0
$startTime = Get-Date
foreach ($item in $folder.Items) {
if ($item -is [Microsoft.Office.Interop.Outlook.MailItem]) {
Process-SingleEmail -emailItem $item -dbConnection $dbConnection
$processedCount++
# Show progress
Write-Progress -Activity "Processing Emails" -Status "Processing email $processedCount of $totalItems" -PercentComplete (($processedCount / $totalItems) * 100)
}
}
$endTime = Get-Date
$duration = ($endTime - $startTime).TotalSeconds
# Close connection
$dbConnection.Close()
# Print summary
Write-Host "Completed processing $processedCount emails in $duration seconds"
Write-Host "Processing speed: $([math]::Round($processedCount / $duration, 2)) emails/second"
}
# Run the main function
Main
The above script follows a straightforward approach:
This approach is simple to implement but can be slow for processing large mailboxes as it handles each email sequentially.
After extracting the raw email data from Outlook, we process it through a Python cleaning script similar to the one used for EML parsing. This script handles common email-specific cleaning tasks including:
This sequential cleaning process faces the same performance limitations as our earlier EML parsing approach, with each email being processed one at a time.
Sequential processing creates significant bottlenecks when handling large datasets. In our case with approximately 1 million emails, the limitations become quickly apparent.
With each email taking 1-2 seconds to process sequentially, our complete dataset would require:
This timeline creates several critical problems:
The traditional answer to big data processing involves systems like:
However, these enterprise-scale solutions introduce unnecessary complexity and cost for our scale. While powerful, they're designed for petabyte-scale operations across distributed infrastructure—overkill for our million-email dataset.
Concurrency and parallel computing are expansive fields, but we don't need their full complexity. We're looking for middle ground—more efficient than sequential processing but simpler than distributed big data frameworks.
Our sequential pipeline has a key characteristic perfect for parallelization: each file processes independently of others. This independence means we can parallelize each step without compromising data integrity.
Fortunately, Linux, Python, and PowerShell all provide robust parallelism tools tailored to different use cases. We'll now explore how these accessible approaches can dramatically reduce processing time without the overhead of enterprise distributed systems.
After identifying the bottlenecks in sequential processing, let's explore three practical parallel implementations across different platforms. Each provides a straightforward approach to parallelism without the complexity of enterprise-scale distributed systems.
GNU Parallel is a shell tool designed to execute jobs in parallel. It's particularly powerful for batch processing files in a Unix/Linux environment.
GNU Parallel takes a simple command that would normally run on a single file and automatically distributes it across multiple CPU cores. It handles the job distribution, monitoring, and output collection, making parallelism accessible without complex coding.
find "/src_path/to/msg_files" -name "*.msg" | parallel -j 8 msgconvert {} --outfile "/dest_path/to/eml_files"/{/.}.eml
In this example:
This simple one-liner can reduce processing time by a factor roughly equal to the number of CPU cores available. On an 8-core system, we might see a 6-7x speedup (accounting for some overhead), reducing a 12-day job to less than 2 days without any complex coding.
Python's multiprocessing library provides a robust way to utilize multiple cores for parallel processing. Unlike threading in Python (limited by the Global Interpreter Lock), multiprocessing creates separate processes that can truly run in parallel.
#!/usr/bin/env python3
import os
from pathlib import Path
import argparse
from multiprocessing import Pool
from tqdm import tqdm
import time
def process_single_email(file_path):
"""
Process a single email file
- Parse the email
- Extract relevant data
- Transform content as needed
"""
# Implementation details abstracted away
email_data = parse_email_file(file_path)
if email_data:
return transform_email_data(email_data)
return None
def parse_email_file(file_path):
"""Parse an email file and return structured data"""
# Implementation details abstracted away
return {...} # Email data dictionary
def transform_email_data(email_data):
"""Process and transform email data"""
# Implementation details abstracted away
return {...} # Processed email data
def save_to_database(processed_data):
"""Save processed email data to database"""
# Implementation details abstracted away
pass
def main():
# Parse command-line arguments
parser = argparse.ArgumentParser(description="Process email files in parallel")
parser.add_argument("--dir", type=Path, default=Path.cwd(), help="Directory with email files")
parser.add_argument("--db-name", default="emails", help="Database name")
parser.add_argument("--jobs", type=int, default=4, help="Number of parallel processes")
args = parser.parse_args()
# Get list of email files
email_files = list(args.dir.glob("*.eml"))
# Initialize database connection
db = initialize_database(args.db_name)
# Start timing
start_time = time.time()
# Process emails in parallel
with Pool(processes=args.jobs) as pool:
# Map the function to all files and collect results
# tqdm wraps the iterator to show a progress bar
results = list(tqdm(
pool.imap(process_single_email, email_files),
total=len(email_files),
desc=f"Processing emails with {args.jobs} workers"
))
# Filter out None results
results = [r for r in results if r]
# Calculate processing time
processing_time = time.time() - start_time
# Save all results to database
save_to_database(results)
print(f"Processed {len(results)} emails in {processing_time:.2f} seconds")
print(f"Processing speed: {len(results)/processing_time:.2f} emails/second")
if __name__ == "__main__":
main()
The key parallel components in this Python script:
Unlike the sequential approach where each email would be processed and immediately saved to the database one-by-one, this parallel implementation:
On an 8-core system, this typically yields a 5-7x speedup over sequential processing, with the bonus of built-in progress tracking and performance metrics.
PowerShell offers several parallelism options, with Runspace Pools being particularly effective for I/O-bound operations like email processing.
# Parallel Outlook Email Processing
# High-level script for extracting emails from Outlook folders and saving to SQLite using parallel processing
# Configuration
$DatabasePath = "C:\path\to\emails.db"
$FolderName = "Inbox"
$MaxJobs = 4 # Number of parallel jobs
function Initialize-Database {
param ($dbPath)
# Load SQLite assembly and create connection
# Implementation details abstracted away
# Return the connection object
return $connection
}
function Process-SingleEmail {
param ($emailItem)
# Extract email properties
$subject = $emailItem.Subject
$body = $emailItem.Body
$htmlBody = $emailItem.HTMLBody
$receivedDate = $emailItem.ReceivedTime
# Process attachments if any
$attachmentData = @()
foreach ($attachment in $emailItem.Attachments) {
$attachmentData += @{
Name = $attachment.FileName
Data = $attachment.PropertyAccessor.GetProperty("http://schemas.microsoft.com/mapi/proptag/0x37010102")
}
}
# Return processed data (will be saved to DB later)
return @{
Subject = $subject
Body = $body
HtmlBody = $htmlBody
ReceivedDate = $receivedDate
Attachments = $attachmentData
}
}
function Save-EmailBatchToDatabase {
param ($emailBatch, $dbConnection)
# Begin transaction for better performance
$transaction = $dbConnection.BeginTransaction()
foreach ($emailData in $emailBatch) {
# Save email to database
# Implementation details abstracted away
# Save attachments if any
foreach ($attachment in $emailData.Attachments) {
# Save attachment to database
# Implementation details abstracted away
}
}
# Commit transaction
$transaction.Commit()
}
function Main {
# Initialize Outlook
$outlook = New-Object -ComObject Outlook.Application
$namespace = $outlook.GetNamespace("MAPI")
# Connect to database
$dbConnection = Initialize-Database -dbPath $DatabasePath
# Get the target folder
$folder = $namespace.Folders.Item(1).Folders.Item($FolderName)
# Get all items
$allItems = @()
foreach ($item in $folder.Items) {
if ($item -is [Microsoft.Office.Interop.Outlook.MailItem]) {
$allItems += $item
}
}
$totalItems = $allItems.Count
Write-Host "Found $totalItems emails to process"
# Process emails in parallel
$startTime = Get-Date
# Create a throttle limit for jobs
$throttleLimit = $MaxJobs
# Create runspace pool
$runspacePool = [runspacefactory]::CreateRunspacePool(1, $throttleLimit)
$runspacePool.Open()
# Create job tracking collections
$jobs = @()
$results = @()
# Create script block for parallel processing
$scriptBlock = {
param ($emailItem)
Process-SingleEmail -emailItem $emailItem
}
# Start parallel jobs
foreach ($item in $allItems) {
$powerShell = [powershell]::Create().AddScript($scriptBlock).AddParameter("emailItem", $item)
$powerShell.RunspacePool = $runspacePool
$jobs += @{
PowerShell = $powerShell
Handle = $powerShell.BeginInvoke()
}
}
# Track progress
$completed = 0
while ($jobs.Handle.IsCompleted -contains $false) {
$completedJobs = $jobs | Where-Object { $_.Handle.IsCompleted -eq $true }
foreach ($job in $completedJobs) {
if ($job.PowerShell.EndInvoke($job.Handle)) {
$results += $job.PowerShell.EndInvoke($job.Handle)
$completed++
# Show progress
Write-Progress -Activity "Processing Emails in Parallel" -Status "Processed $completed of $totalItems" -PercentComplete (($completed / $totalItems) * 100)
}
# Clean up resources
$job.PowerShell.Dispose()
$jobs.Remove($job)
}
# Small sleep to prevent CPU spinning
Start-Sleep -Milliseconds 100
}
# Process any remaining jobs
foreach ($job in $jobs) {
$results += $job.PowerShell.EndInvoke($job.Handle)
$job.PowerShell.Dispose()
}
# Save all results to database in batches
$batchSize = 100
for ($i = 0; $i -lt $results.Count; $i += $batchSize) {
$batch = $results[$i..([Math]::Min($i + $batchSize - 1, $results.Count - 1))]
Save-EmailBatchToDatabase -emailBatch $batch -dbConnection $dbConnection
}
# Calculate processing time
$endTime = Get-Date
$duration = ($endTime - $startTime).TotalSeconds
# Close resources
$runspacePool.Close()
$runspacePool.Dispose()
$dbConnection.Close()
# Print summary
Write-Host "Completed processing $totalItems emails in $duration seconds"
Write-Host "Processing speed: $([math]::Round($totalItems / $duration, 2)) emails/second"
Write-Host "Using $MaxJobs parallel jobs"
}
# Run the main function
Main
The PowerShell parallelism implementation offers several key advantages over the sequential approach:
This approach separates the extraction phase from the storage phase, allowing each to be optimized independently. By processing multiple emails concurrently and then saving in efficient batches, we achieve both parallelism benefits and database optimization.
On a typical workstation, this parallel PowerShell approach can yield a 4-6x performance improvement over sequential processing for Outlook extraction tasks, turning a multi-week project into a few days of processing.
To demonstrate the real-world impact of parallel processing, we conducted benchmarks using GNU Parallel with the msgconvert tool across varying workloads and parallelism levels.
The benchmark results clearly illustrate how parallel processing transforms the performance curve:
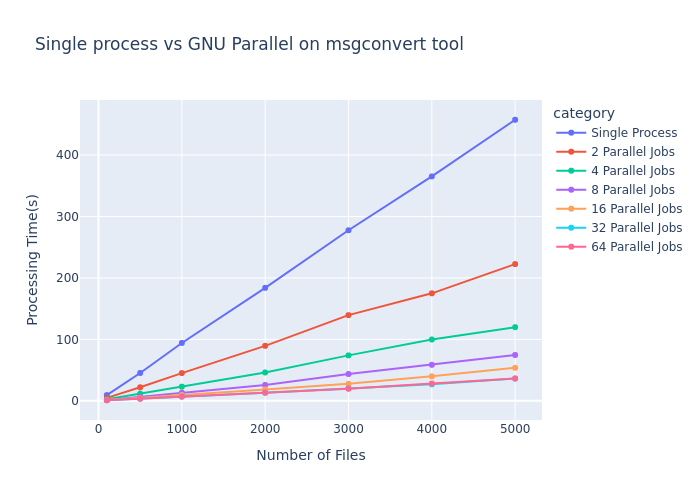
As shown in the graph, the performance gains follow Amdahl's Law, where:
The most significant observations:
The benchmark reveals an important practical consideration: hardware limitations establish an upper bound on parallelism benefits. Note how the lines for 32 and 64 parallel jobs nearly overlap, indicating we've reached the parallelization ceiling for this workload on the test hardware.
This plateau occurs due to several factors:
While these benchmarks specifically measure GNU Parallel performance, similar scaling patterns emerge when using Python's multiprocessing library and PowerShell's RunspacePool. The fundamental performance characteristics—initial linear scaling followed by diminishing returns—remain consistent across all three implementations, though the exact efficiency curve varies based on implementation details.
For optimal performance across any platform, these results suggest configuring parallelism to match your hardware capabilities—typically setting job count to match or slightly exceed your CPU core count provides the best balance of performance gain versus resource consumption.
Our journey through parallel processing implementations reveals crucial lessons for AI practitioners working with real-world data:
In the age of Generative AI, where model quality depends directly on data quality, these parallelization techniques serve as the unsung heroes of AI development pipelines. By reducing data processing time from weeks to days, they enable faster iteration cycles, more experimental approaches, and ultimately better AI solutions—keeping pace with the rapidly evolving GenAI landscape without requiring enterprise-scale infrastructure investments.

In the era of Generative AI, the quality and scale of data processing have become more critical than ever. While sophisticated language models and ML algorithms steal the spotlight, the behind-the-scenes work of data preparation remains the unsung hero of successful AI implementations.
The world of artificial intelligence is constantly evolving, and one of the most captivating areas of progress is in the realm of voice technology. Recently, a new contender has emerged, generating significant buzz and excitement within the AI community and beyond: the Sesame voice model, officially known as the Conversational Speech Model (CSM). This technology has rapidly garnered attention for its remarkable ability to produce speech that sounds strikingly human, blurring the lines between artificial and natural communication. Initial reactions have been overwhelmingly positive, with users and experts alike expressing astonishment at the model's naturalness and emotional expressiveness. Some have even noted the difficulty in distinguishing CSM's output from that of a real person, signaling a potential breakthrough in overcoming the long-sought-after "uncanny valley" of artificial speech. This achievement is particularly noteworthy as it promises to make interactions with AI feel less robotic and more intuitive, potentially revolutionizing how we engage with technology.
The pursuit of realistic AI voice is a pivotal milestone in the broader journey of artificial intelligence. For years, the robotic and often monotone nature of AI speech has been a barrier to seamless human-computer interaction. The ability to generate voice that conveys emotion, nuance, and natural conversational flow is crucial for creating truly useful and engaging AI companions. Sesame AI, the team behind this innovation, aims to achieve precisely this. Their mission is centered around creating voice companions that can genuinely enhance daily life, making computers feel more lifelike by enabling them to communicate with humans in a natural and intuitive way, with voice being a central element. The core objective is to attain what they term "voice presence" - a quality that makes spoken interactions feel real, understood, and valued, fostering confidence and trust over time. This blog post will delve into the intricacies of the Sesame voice model, exploring its architecture, key features, performance compared to other models, potential applications, ethical considerations, and the implications of its recent open-source release.
The technology at the heart of the recent excitement is officially named the "Conversational Speech Model," or CSM. This model represents a significant advancement in the field of AI speech synthesis, designed with the explicit goal of achieving real-time, human-like conversation The team at Sesame AI is driven by a clear mission: to develop voice companions that are genuinely useful in the everyday lives of individuals This involves not just the generation of speech, but the creation of AI that can see, hear, and collaborate with humans naturally. A central tenet of their approach is the focus on natural human voice as the primary mode of interaction. The ultimate aim of their research and development efforts is to achieve "voice presence". This concept goes beyond mere clarity of pronunciation; it encompasses the ability of an AI voice to sound natural, believable, and to create a sense of genuine connection and understanding with the user It's about making the interaction feel less like a transaction with a machine and more like a conversation with another intelligent being.
The remarkable naturalness of the Sesame voice model is underpinned by a sophisticated technical architecture that departs from traditional text-to-speech (TTS) methods. A key aspect of CSM is its end-to-end multimodal architecture. Unlike conventional TTS pipelines that first generate text and then synthesize audio as separate steps, CSM processes both text and audio context together within a unified framework. This allows the AI to essentially "think" as it speaks, producing not just words but also the subtle vocal behaviors that convey meaning and emotion. This is achieved through the use of two autoregressive transformer networks working in tandem. A robust backbone processes interleaved text and audio tokens, incorporating the full conversational context, while a dedicated decoder reconstructs high-fidelity audio. This design enables the model to dynamically adjust its output in real-time, modulating tone and pace based on previous dialogue cues.
Another crucial element is the advanced tokenization via Residual Vector Quantization (RVQ) CSM employs a dual-token strategy using RVQ to deliver the fine-grained variations that characterize natural human speech, allowing for dynamic emotional expression that traditional systems often lack. This involves two types of learned tokens: semantic tokens, which capture the linguistic content and high-level speech traits, and acoustic tokens, which preserve detailed voice characteristics like timbre, pitch, and timing. By operating directly on these discrete audio tokens, CSM can generate speech without an intermediate text-only step, potentially contributing to its increased expressivity.
Furthermore, CSM incorporates context-aware prosody modeling. In human conversation, context is vital for determining the appropriate tone, emphasis, and rhythm. CSM addresses this by processing previous text and audio inputs to build a comprehensive understanding of the conversational flow. This context then informs the model's decisions regarding intonation, rhythm, and pacing, allowing it to choose among numerous valid ways to render a sentence. This capability allows CSM to sound more natural in dialogue by adapting its tone and expressiveness based on the conversation's history.
Training high-fidelity audio models is typically computationally intensive. CSM utilizes efficient training through compute amortization to manage memory overhead and accelerate development cycles. The model's transformer backbone is trained on every audio frame, capturing comprehensive context, while the audio decoder is trained on a random subset of frames, significantly reducing memory requirements without sacrificing performance.
Finally, the architecture of CSM leverages a Llama backbone from Meta, a testament to the power of transfer learning in AI. This robust language model foundation is coupled with a smaller, specialized audio decoder that produces Mimi audio codes. This combination allows CSM to benefit from the linguistic understanding capabilities of the Llama architecture while having a dedicated component focused on generating high-quality, natural-sounding audio.
Several key capabilities contribute to the exceptional performance and lifelike quality of the Sesame voice model. One of the most significant is its emotional intelligence. CSM is designed to interpret and respond to the emotional context of a conversation, allowing it to modulate its tone and delivery to match the user's mood. This includes the ability to detect cues of emotion and respond with an appropriate tone, such as sounding empathetic when the user is upset, and even demonstrating a prowess in detecting nuances like sarcasm.
Another crucial capability is contextual awareness and memory, CSM adjusts its output based on the history of the conversation, allowing it to maintain coherence and relevance over extended dialogues. By processing previous text and audio inputs, the model builds a comprehensive understanding of the conversational flow, enabling it to reference earlier topics and maintain a consistent style.
The model also exhibits remarkable natural conversational dynamics. Unlike the often rigid and stilted speech of older AI systems, CSM incorporates natural pauses, filler words like "ums," and even laughter, mimicking the way humans naturally speak. It can also handle the timing and flow of dialogue, knowing when to pause, interject, or yield, contributing to a more organic feel. Furthermore, it demonstrates user experience improvements such as gradually fading the volume when interrupted, a behavior more akin to human interaction.
The voice cloning potential of CSM is another highly discussed capability. The model has the ability to replicate voice characteristics from audio samples, even with just a minute of source audio. While the open-sourced base model is not fine-tuned for specific voices, this capability highlights the underlying power of the technology to capture and reproduce the nuances of individual voices.
Enabling a fluid and responsive conversational experience is the real-time interaction and low latency of CSM. Users have reported barely noticing any delay when interacting with the model. Official benchmarks indicate an end-to-end latency of less than 500 milliseconds, with an average of 380ms, facilitating a natural back-and-forth flow in conversations.
Finally, while currently supporting multiple languages including English, CSM's multilingual support is somewhat limited at present, with the model being primarily trained on English audio. There are plans to expand language support in the future, but the current version may struggle with non-English languages due to data contamination in the training process.
The emergence of Sesame's CSM has naturally led to comparisons with existing prominent voice models from companies like Open AI, Google, and others. In many aspects, Sesame has been lauded for its superior naturalness and expressiveness. Users and experts often compare it favorably to Open AI's ChatGPT voice mode, Google's Gemini, as well as more established assistants like Siri and Alexa. Many find CSM's conversational fluency and emotional expression to surpass those of mainstream models. Some have even described the realism as significantly more advanced, with the AI performing more like a human with natural imperfections rather than a perfect, but potentially sterile customer service agent.
A key strength of Sesame lies in its conversational flow. It is often noted for its organic and flowing feel, making interactions feel more like a conversation with a real person. The model's ability to seamlessly continue a story or conversation even after interruptions is a notable improvement over some other AI assistants that might stumble or restart in such situations.
However, there are potential limitations. The open-sourced version, CSM-1B, is a 1-billion-parameter model. While this size allows it to run on more accessible hardware it might also impact the overall depth and complexity of the language model compared to the much larger models behind systems like ChatGPT or Gemini. Some users have suggested that while Sesame excels in naturalness, it might be less "deep and complex" or less strong in following specific instructions compared to these larger counterparts. Additionally, the model seems to perform best with shorter audio snippets, such as sentences, rather than lengthy paragraphs.
Despite these potential limitations, Sesame introduces notable UX improvements. Features like the gradual fading of volume when the user interrupts feel more natural and human-like compared to the abrupt stop soften encountered with other voice assistants.
To provide a clearer comparison, the following table summarizes some key differences and similarities between Sesame (CSM) and other prominent voice models based on the available information:
This comparison suggests that Sesame's primary strength lies in the quality and naturalness of its voice interaction. While it might not have the sheer breadth of knowledge or instruction-following capabilities of larger language models, its focus on creating a truly human-like conversational experience positions it as a significant advancement in the field.
The exceptional realism and natural conversational flow of the Sesame voice model open up a wide array of potential applications across various industries and in everyday life. One of the most immediate and impactful areas is in enhanced AI assistants and companions. By creating more lifelike and engaging interactions, Sesame's technology could lead to AI companions that feel more like genuine conversational partners, capable of building trust and providing more intuitive support.
The potential for revolutionizing customer service is also significant. Imagine customer support interactions that feel empathetic and natural, where the AI can truly understand and respond to the customer's emotional state. This could lead to more positive customer experiences and potentially reduce operational costs for businesses.
Furthermore, Sesame's technology could greatly contribute to improving accessibility for individuals with disabilities, offering more natural and engaging ways to interact with technology through voice.
In the realm of content creation, CSM could be a game-changer for audiobooks, podcasts, and voiceovers. The ability to generate highly realistic voices with natural emotional inflections could make listening experiences far more engaging and immersive.
Education and training could also be transformed, with AI tutors and learning tools that can engage students in more natural and personalized ways.
The healthcare industry presents numerous possibilities. Applications in AI doctors for initial consultations, triage, and even generating medical notes during patient interactions could become more effective and user-friendly with a natural-sounding voice.
The integration of Sesame's voice model into smart devices and the Internet of Things (IoT) could lead to more natural and intuitive voice interfaces in cars, homes, and wearable technology like the lightweight eyewear being developed by Sesame themselves. This could move beyond simple commands to more fluid and context-aware interactions.
Augmented reality applications could also benefit, with natural voice interactions enhancing immersive experiences and providing a moreseamless way to interact with digital overlays in the real world.
The natural dialogue and low latency of CSM could streamline voice commerce, making voice-activated purchases a more viable and user-friendly option.
Finally, by analyzing conversations and user preferences, AI powered by Sesame could offer personalized content recommendations in a more natural and engaging way, strengthening brand connections and user engagement.
The remarkable realism of the Sesame voice model, particularly its voice cloning potential, brings forth significant ethical considerations that must be carefully navigated. One of the primary concerns is the risk of impersonation and fraud. The ability to easily replicate voices opens the door to malicious actors potentially using this technology to mimic individuals for fraudulent purposes, such as voice phishing scams, which could become alarmingly convincing.
The potential for misinformation and deception is another serious concern, AI-generated speech could be used to create fake news or misleading content, making it difficult for individuals to discern what is real and what is fabricated.
Interestingly, Sesame has opted for a reliance on an honor system and ethical guidelines rather than implementing strict built-in technical safeguards against misuse. While the company explicitly prohibits impersonation, fraud, misinformation, deception, and illegal or harmful activities in its terms of use, the ease with which voice cloning can be achieved raises questions about the effectiveness of these guidelines alone. This approach places a significant responsibility on developers and users to act ethically and avoid misusing the technology.
Beyond the immediate risks of misuse, there are also privacy concerns related to the analysis of conversations, particularly if this technology becomes integrated into everyday devices. Robust data security and transparency will be crucial to address these concerns and comply with regulations like GDPR.
Finally, the very realism of the voice model could lead to unforeseen psychological implications. As AI voices become increasingly human-like, some users might develop emotional attachments, blurring the lines between human and artificial interaction. The feeling of "uncanny discomfort" that can arise from interacting with something almost, but not quite, human is also a factor to consider.
A significant development in the story of the Sesame voice model is the decision by Sesame AI to release its base model, CSM-1B, as open source under the Apache 2.0 license. This move has profound implications for the future of voice technology. The model and its checkpoints are readily available on platforms like GitHub and Hugging Face, making this advanced technology accessible to developers and researchers worldwide.
The Apache 2.0 license is particularly significant as it allows for commercial use of the model with minimal restrictions. This has the potential to foster rapid innovation and research in the field of conversational AI, as the community can now build upon and improve the model, explore its capabilities, and discover new applications.
This open-source release marks a step towards the democratization of high-quality voice synthesis. For years, advanced voice technology has been largely controlled by major tech companies. By making CSM-1B available, Sesame is empowering smaller companies and independent developers who might not have the resources to build proprietary voice systems from scratch. This could lead to a proliferation of new applications and integrations of natural-sounding speech in various products and services, potentially inspiring creative implementations in unexpected places, from new cars to next-generation IoT devices.
To utilize the open-source CSM-1B model, certain requirements typically need to be met, including a CUDA-compatible GPU, Python 3.10 or higher, and a Hugging Face account with access to the model repository. Users also need to accept the terms and conditions on Hugging Face to gain access to the model files. It's important to note that the open-sourced CSM-1B is a base generation model, meaning it is capable of producing a variety of voices but has not been fine-tuned on any specific voice. Further fine-tuning may be required for specific use cases, including voice cloning for particular individuals.
The Sesame voice model, particularly its Conversational Speech Model (CSM), represents a significant leap forward in the field of AI voice technology. Its ability to generate speech with remarkable naturalness and emotional expressiveness has captured the attention of the AI community and sparked discussions about the future of human-computer interaction. The model's end-to-end multimodal architecture, advanced RVQ tokenization, and context-aware prosody modeling contribute to a level of realism that often surpasses existing mainstream voice models.
The potential applications of this technology are vast, spanning across AI assistants, customer service, content creation, healthcare, smart devices, and more. The heightened realism promises to create more intuitive and engaging experiences for users across various domains.
However, the power of Sesame's voice model also brings forth critical ethical considerations, primarily concerning the risks of impersonation, fraud, and the spread of misinformation through voice cloning. The reliance on ethical guidelines and an honor system underscores the importance of responsible development and use of this technology.
The decision by Sesame AI to open-source its base model, CSM-1B, under the Apache 2.0 license is a pivotal moment. This democratization of advanced voice technology has the potential to accelerate innovation, foster new applications, and empower a wider community of developers and researchers to contribute to the evolution of conversational AI.
In conclusion, Sesame AI is not just improving AI speech; it is setting a new standard for what is possible in human-computer interaction through voice. By pushing the boundaries of realism and naturalness, Sesame is shaping a future where our conversations with artificial intelligence can be more seamless, engaging, and ultimately, more human.

The Dawn of Believable AI Voices explores Sesame's advanced conversational speech model, highlighting its breakthrough in generating natural, expressive AI voices that enhance human-computer interactions.
Yes AI is spreading like wildfire. It is revolutionizing all industries including manufacturing. It offers solutions that enhance efficiency, reduce costs, and drive innovation - through Demand prediction, real-time quality control, smart automation, and predictive maintenance. The list shows how AI can cut costs, reduce downtime, and surpass various roadblocks in manufacturing processes.
A recent survey by Deloitte revealed that over 80% of manufacturing professionals reported that labor turnover had disrupted production in 2024. This disruption is anticipated to persist, potentially leading to delays and increased costs throughout the value chain in 2025.
Artificial Intelligence (AI) can help us take great strides here - reducing cost and enhancing efficiency. Research shows that the global AI in the manufacturing market is poised to be valued at $20.8 billion by 2028. Let's see some most practical uses that are already being implemented:

Accurate demand forecasting is crucial for manufacturers to balance production and inventory levels. Overproduction leads to excess inventory and increased costs, while underproduction results in stockouts and lost sales. AI-driven machine learning algorithms analyze vast amounts of historical data, including seasonal trends, past sales, and buying patterns, to predict future product demand with high accuracy. These models also incorporate external factors such as market trends and social media sentiment, enabling manufacturers to adjust production plans in real-time in response to sudden market fluctuations or supply chain disruptions. Implementing AI in demand forecasting leads to better resource management, improved environmental sustainability, and more efficient operations.

Supply chain optimization is a critical aspect of manufacturing that directly impacts revenue management. AI enhances supply chain operations by providing real-time insights into various factors such as demand patterns, inventory levels, and logistics. By analyzing this data, AI systems can predict demand fluctuations, optimize inventory management, and streamline logistics, leading to reduced operational costs and improved customer satisfaction. For instance, AI can automate the generation of purchase orders or replenishment requests based on demand forecasts and predefined inventory policies, ensuring that manufacturers maintain optimal stock levels without overproduction.

Maintaining high-quality standards is essential in manufacturing, and AI plays a significant role in enhancing quality control processes. By integrating AI with computer vision, manufacturers can detect product defects in real-time with high accuracy. For example, companies like Foxconn have implemented AI-powered computer vision systems to identify product errors during the manufacturing process, resulting in a 30% reduction in product defects. These systems can inspect products for defects more accurately and consistently than human inspectors, ensuring high standards are maintained.

Mining, metals, and other heavy industrial companies lose 23 hours per month to machine failures, costing several millions of dollars.
Unplanned equipment downtime can lead to significant financial losses in manufacturing. AI addresses this challenge through predictive maintenance, which involves analyzing data from various sources such as IoT sensors, PLCs, and ERPs to assess machine performance parameters. By monitoring these parameters, AI systems can predict potential equipment failures before they occur, allowing for timely maintenance interventions. This approach minimizes unplanned outages, reduces maintenance costs, and extends the lifespan of machinery. For instance, AI algorithms can study machine usage data to detect early signs of wear and tear, enabling manufacturers to schedule repairs in advance and minimize downtime.

AI enhances product design and development by enabling manufacturers to explore innovative configurations that may not be evident through traditional methods. Generative AI allows for the exploration of various design possibilities, optimizing product performance and material usage. AI-driven simulation tools can virtually test these designs under different conditions, reducing the need for physical prototypes and accelerating the development process. This approach not only shortens time-to-market but also results in products that are optimized for performance and cost-effectiveness.
Several leading manufacturers have successfully implemented AI to enhance their operations:



The integration of AI in manufacturing is not just a trend but a necessity for staying competitive in today's dynamic market. By adopting AI technologies, manufacturers can enhance operational efficiency, reduce costs, and drive innovation. As the industry continues to evolve, embracing AI will be crucial for meeting the demands of the ever-changing manufacturing landscape.
In conclusion, AI offers transformative potential for the manufacturing industry, providing practical solutions that address key challenges and pave the way for a more efficient and innovative future. Want to make a leap in your manufacturing process? Let's do it!
The integration of AI in manufacturing can enhance operational efficiency, reduce costs, and drive innovation - with predictive analysis, supply chain optimization and much more. Read 5 such use cases of AI in the manufacturing industry.
Everyone wants to develop an AI engine for themselves. Everyone has a valid use case where they can integrate an AI system to bring in multiple benefits. Generative AI, multimodal models, and real-time AI-powered automation have unlocked new possibilities across industries. But the question is how to pull it off. What will it cost? Is it better to hire a team or outsource? What are the criteria to keep in mind?
First of all, developing AI solutions is no longer just about machine learning models - it involves leveraging pre-trained LLMs, fine-tuning models for specific applications, and optimizing AI deployments for cost and efficiency. Hence a structured approach to cost estimation, pricing models, and return on investment (ROI) calculations are necessary.
The cost of AI development can vary based on several factors, including the complexity of the model, data requirements, computational infrastructure, integration needs, and the development team's expertise.

Let’s look deeper into each of them.
AI models today range from fine-tuned pre-trained models (e.g., OpenAI GPT-4, Gemini, Claude) to enterprise-specific LLMs trained on proprietary data. The complexity of the model directly impacts development costs.
In this context, the cost implications can include:

But in general, the complexity and cost has drastically come down in comparison to previous years, thanks to instantaneous advances in Gen AI models.
Generative AI relies on high-quality, curated datasets for domain-specific fine-tuning.

AI models require significant computing resources, whether running on cloud GPUs or fine-tuning with on-premise AI accelerators.

Integrating AI solutions into existing IT environments can be challenging due to compatibility issues. Thus costs can arise from:
The team structure typically includes:

Many startups and mid-sized businesses outsource AI development to reduce costs, leveraging pre-trained models and cloud-based AI solutions instead of building models from scratch.
AI models require continuous fine-tuning, monitoring, and scaling.




AI development in 2025 is more accessible yet cost-intensive, depending on the level of customization. GenAI, API-based AI services, and fine-tuned models are making AI development less complex, faster and more cost-effective. For this, companies must carefully evaluate the resources they are getting for their money and parallelly look into pricing models to justify AI investments.
At Techjays, we are at the cusp of the AI revolution. We were one of the first companies to focus fully on the AI domain after a decade of service in the IT industry. Here at Techjays, we specialize in AI-driven product development, from fine-tuned LLM solutions to enterprise AI integrations.
So it's time to get to work! Let’s build your idea with AI.

AI solutions involve leveraging pre-trained LLMs, fine-tuning models for specific applications, and optimizing AI deployments for cost and efficiency. Hers's a structured approach to cost estimation, pricing models, and return on investment (ROI) calculations


.svg)

.png)







