Understanding Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an advanced AI architecture that combines two key components, a retriever to fetch relevant information from an external knowledge source and a generator (a large language model) to create human-like responses using that information.
Understanding Retrieval-Augmented Generation (RAG)
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced AI architecture that combines two key components:
1. A retriever to fetch relevant information from an external knowledge source.
2. A generator (a large language model) to create human-like responses using that information.
Unlike traditional language models that rely only on internal training, RAG can pull in fresh, factual data from outside sources — making it smarter, more accurate, and less prone to hallucinations.
Where is RAG Used?
RAG is ideal for any task that requires current, factual, or domain-specific information.
Examples include:
- Customer Support Chatbots
- Search Engines
- Enterprise Knowledge Assistants
- Scientific/Medical Question Answering
- Document Summarization with References
- Legal Document Analysis
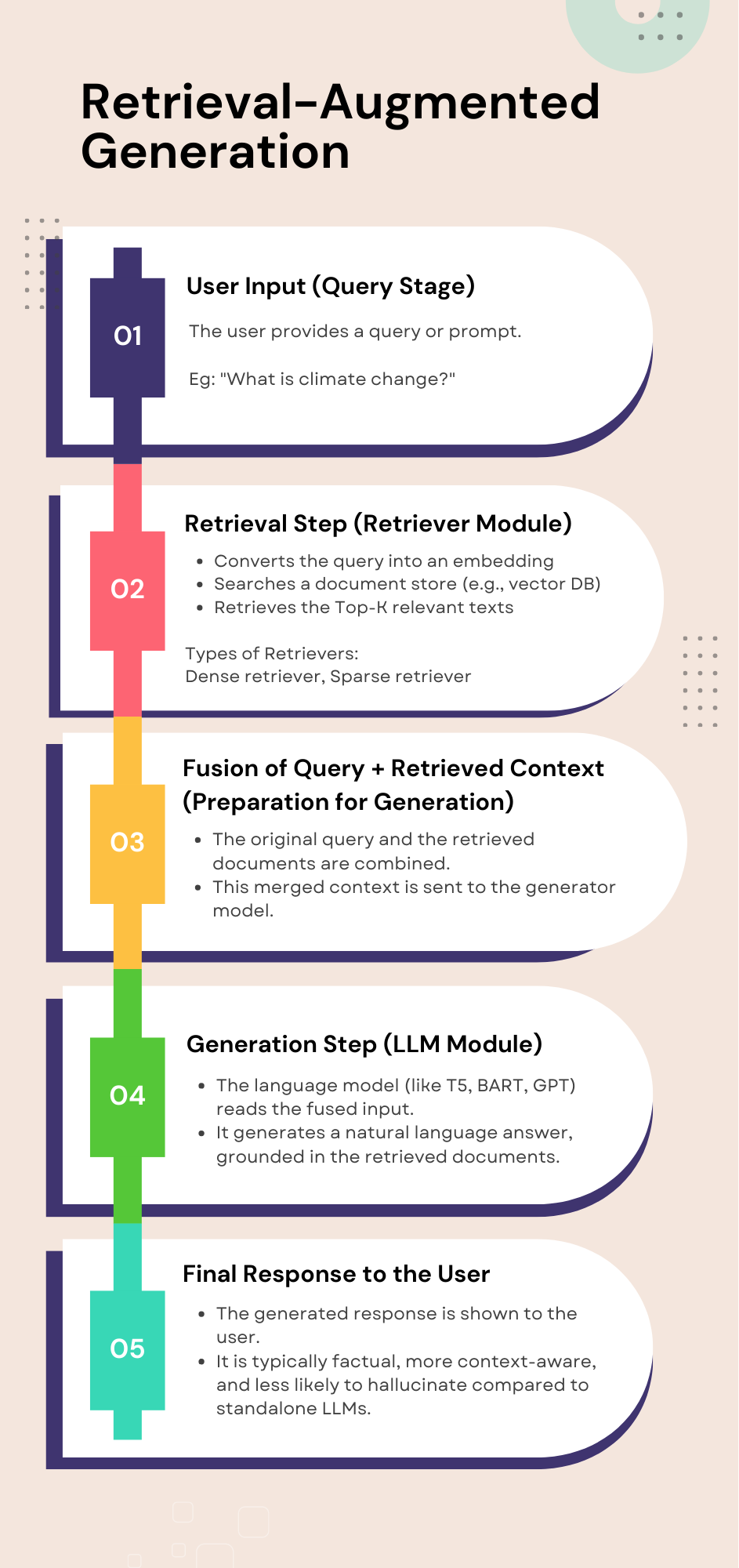
How RAG Works (Step-by-Step)
1. User Query
- User asks a question (e.g., "What causes global warming?")
2. Retriever
- Converts the query into an embedding
- Searches a document store (e.g., vector database)
- Retrieves the Top-K relevant texts
3. Fused Input
- The system combines the original question with the retrieved texts
- Creates a new prompt with richer context
4. Generator (LLM)
- A language model (e.g., GPT, T5, BART) uses this fused input
- Generates a natural, fact-based answer
5. Final Output
- The answer is returned to the user, grounded in actual documents
Why Use RAG? (Benefits)
- Reduces hallucinations
- Allows up-to-date, dynamic knowledge injection
- More scalable than retraining LLMs
- Great for specialized, high-trust domains
Challenges
- If retrieval quality is low, output suffers
- Context length limits in LLMs
- High compute cost for large-scale implementations

As a Software Developer at Techjays, I focus on designing and delivering bespoke WordPress websites that align with diverse client requirements. My background in computer technology, complemented by an advanced MBA in Information Systems, allows me to merge technical proficiency with business acumen to achieve project success.

